Http cache
HTTP 协议是一种无状态的“松散协议”,它不会记录不同请求的状态,并且因为它本身包含了两端(客户端和服务端),根据请求和响应来区分,它大部分的内容都只是一个建议,其实双边是可以不遵守此建议的。
例如:服务端说,这个数据缓存有一天的时效性,但是客户端可以说,我不听我不听,我就要每次去重新请求。
浏览器是天然支持 HTTP 缓存,开源库则需要进行一些例如存规则和缓存的资源存放路径之类的简单设定。
- 缓存失效策略
response header: Cache-Control: max-age=120 // 单位s ETag:”121321456465aaddb”
// 上古时期还会使用 expires 来决定超时的日期,但是已经被废弃了,如果和 Cache-Control 同时存在,以 Cache-Control 为准。
在此时间间隔范围内,客户端不会再向服务端发送新的请求。当资源距离上一次缓存的时间间隔,大于 120 秒后,客户端才会再次向服务端发送请求。
Cache-Control 是在 HTTP/1.1 中被定义的,它可以用于取代之前的缓存策略,现在所有的浏览器都支持 Cache-Control ,它已经成为一种通用的标准。
- “public” 和 “private”
“public” 是一种默认的策略,表示当前缓存是开放的,任何请求响应的中间环节,都可以对其进行缓存,如果我们不显式指定,则当前为 “public” 缓存。
与之相对的 “private”,则表示当前响应是针对单个用户的,并非通用数据,因此不建议任何中间缓存对其进行缓存。例如:浏览器就是一个比较私人的缓存源,它会缓存 “private” 的缓存,而 CDN 则不会。
而 HTTP 缓存,也是依赖于 URL 的,注意 URL 是大小写敏感的,同一个 URL 表示同一个请求响应,依此来判断缓存和后续缓存的复用。
浏览器的缓存策略
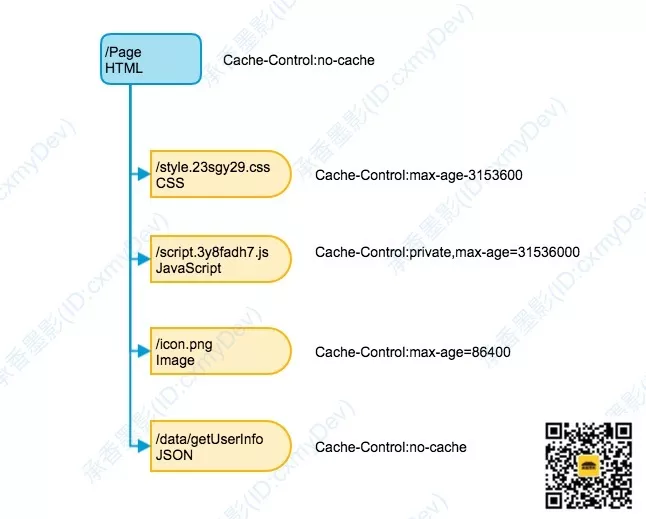
到这里就很好理解了:
HTML 页面,使用 no-cache,强制每次都向源服务器确认数据。
CSS文件通常变动的频率非常低,所以可以允许中间层缓存,并且缓存时间为一年不过期。
JavaScript内有业务逻辑,可以设定为只允许客户终端缓存。
getUserInfo,是为个人用户数据相关,这里推荐可缓存,但是需要每次向服务器重新确认。