Week41
- 1. 代码如何支持重来?
- 2. 代码分类
- 3. 系统调用阻塞线程是如何实现的?
- 4. IO 多路复用 & reactor网络编程模型
- 5. blockingQueue 批量处理
- 6. BFS,DFS
- 7. java hashmap 为何不实现缩容
- 8. MESI
1. 代码如何支持重来?
https://mp.weixin.qq.com/s/XRJjsa0ZJNKJR2eOkJWjEQ
- 大量使用全局变量
- 全局变量没有对应的清理复位逻辑
全局变量记录了状态,有状态的代码是不能轻易重复执行的, 相当于接口里要处理幂等逻辑。
没有状态, 其实相当于每次都执行 创建上下文 + 执行代码
带有状态, 其实相当于每次需要 恢复上下文 + 执行代码
恢复一个复杂的上下文, 是很困难的, 甚至于是不可能的。
2. 代码分类
- 功能代码(业务需求强相关,力求高内聚)
- 控制代码(控制、组合业务流程。 偏灵活性)
- 运维代码(方便观测,排查问题。 log, metric,告警等)
代码运行起来后,就是个黑盒子, 是不可见的。 通过log, metric 提高代码的可见性。
3. 系统调用阻塞线程是如何实现的?
- 从CPU角度看,阻塞就是让出CPU, 让CPU去执行了其他的指令流。
- 从OS角度看, 阻塞就是把线程移到等待队列, 等到线程需要的资源(网络数据, 磁盘文件,锁,条件变量,信号灯)满足了,再把移动到就绪队列调度执行。
OS是如何知道这些条件满足了?
回调机制。
- 指令周期(
取指令 + 分析指令 + 执行指令) - 始终周期(CPU频率、时钟)
CPU会在每个指令周期,检查一下中断标志位, 如果有中断,会保存现场, 然后去执行中断代码。
网络数据包、磁盘文件读取完成是 ,网卡、磁盘控制器会设置硬中断,然后CPU就执行中断程序, OS就知道阻塞的资源满足了。
4. IO 多路复用 & reactor网络编程模型
IO多路复用, 就是一个线程可以监视多个文件句柄(fd)
- 单reactor 单线程 (select, accept, read,write, process在一个线程)
- 单reactor 多线程 (select, accept, read,write 在reacotr线程, process 在线程池)
- 多reacotr 多线程 (mainReactor 执行 selecy,accept, 其他reactor执行 select, read,process,write)
5. blockingQueue 批量处理
当 LinkedList 不是列表时,速度快的兔子都追不上!
blockingQueue 正常方式是一个一个处理,数据量太大时也可以用批量的方式来处理。
// take阻塞读取,有数据时被唤醒,
Order order = blockingQueue.take();
List<Order> orders = new ArrayList<>(100);
blockingQueue.drainTo(orders,100-1);
orders.add(order);
6. BFS,DFS
- BFS, breadth fisrt
- DFS, depth first
- BFS, DFS 本质都是暴力穷举
- BFS, start-> target 的最短路径,空间复杂度会高 O(n),最后一层会存储所有的叶子节点。
- DFS,其实就是回溯算法(backtrack),用递归实现。 空间复杂度低一点 O(logn).
7. java hashmap 为何不实现缩容
启用指针压缩后,table数组中, 一个Node指针占用内存空间32Bit, 4Byte.
算算也是, 2^10 毕竟才 4KB, 这种小map影响不大。
即使是 2^20(1,000,000个key) 也才4MB 这种大规模的map实际 key,value的空间将远远大于4MB, key,value 能正常就对系统整体影响不大。
(考虑一种情况, 已经扩容这么大, 说明实际是需要这么多的 ,即使当前已经删掉了大部分;保留这个数组以备将来使用, 避免将来又要复制扩容,倒也不是不可以)。
当然, 如果已经明确不需要了, map size 太小的话可以忽略; map size 大的话,写代码时就要注意下手动回收下。
note: 扩容更多考虑的是冲突程度(负载压力),尽量保证put,get时间复杂度为O(1).
8. MESI
既然CPU有缓存一致性协议(MESI),为什么JMM还需要volatile关键字? - 码海的回答 - 知乎
volatile CPU硬件工程师给程序员留的一个口子, 用来告诉CPU对这个变量的读写不要瞎优化, 不要乱序、也不要流水线、storeBuffer、invalidateQueue 也暂时用同步的方式来工作, 这个才能保证变量的读写结果和程序员的预期一致。
volatile 相当于把对MESI协议的优化(store buffer, invalidate queue)禁用,临时恢复到cache强一致性。
volatile变量的读写效率肯定比普通变量低, 但是多线程代码的首要目标是要保证正确性, 其次才是性能。
所以, 代码设计时, 多线程之间能不共享变量就不共享; 一是代码简单容易理解, 二是执行效率也更高。
- 首先为了解决 CPU 从 内存读取数据的瓶颈,引入了 Cache,
- 这样虽然提高了 CPU 的执行效率,但又引入了数据的一致性问题,于是为了解决这个问题,工程师又引入了 MESI 缓存一致性,
- 但如果 CPU 间严格的遵守 MESI 协议,会导致执行效率大幅度降低,于是为了妥协又引入了 store buffer 和 Invalidate Queue,
- 不过这样的话数据就由强一致性变成了弱一致性,可能会造成短时间内读取数据的不一致,会导致 bug,于是又引入了内存屏障来保证了数据的可见性,volatile 其实就是用来在变量前后添加内存屏障以保障可见性的
编译器的各种优化(调整访存顺序、常量值替换等),CPU的各种优化(流水线、乱序执行、分支预测)等等,
有个前提: 它们都是基于单线程考虑的,把指令流当做一条完整的线, 中间不会穿插其他指令来修改变量。 但是用多线程提高性能时,破坏了这个假设,所以多个线程的指令流会同时修改变量,前面的优化手段就会导致非预期的执行流程,需要用 lock, volatile 来临时禁用这种优化,保证代码的指令流的正确性。
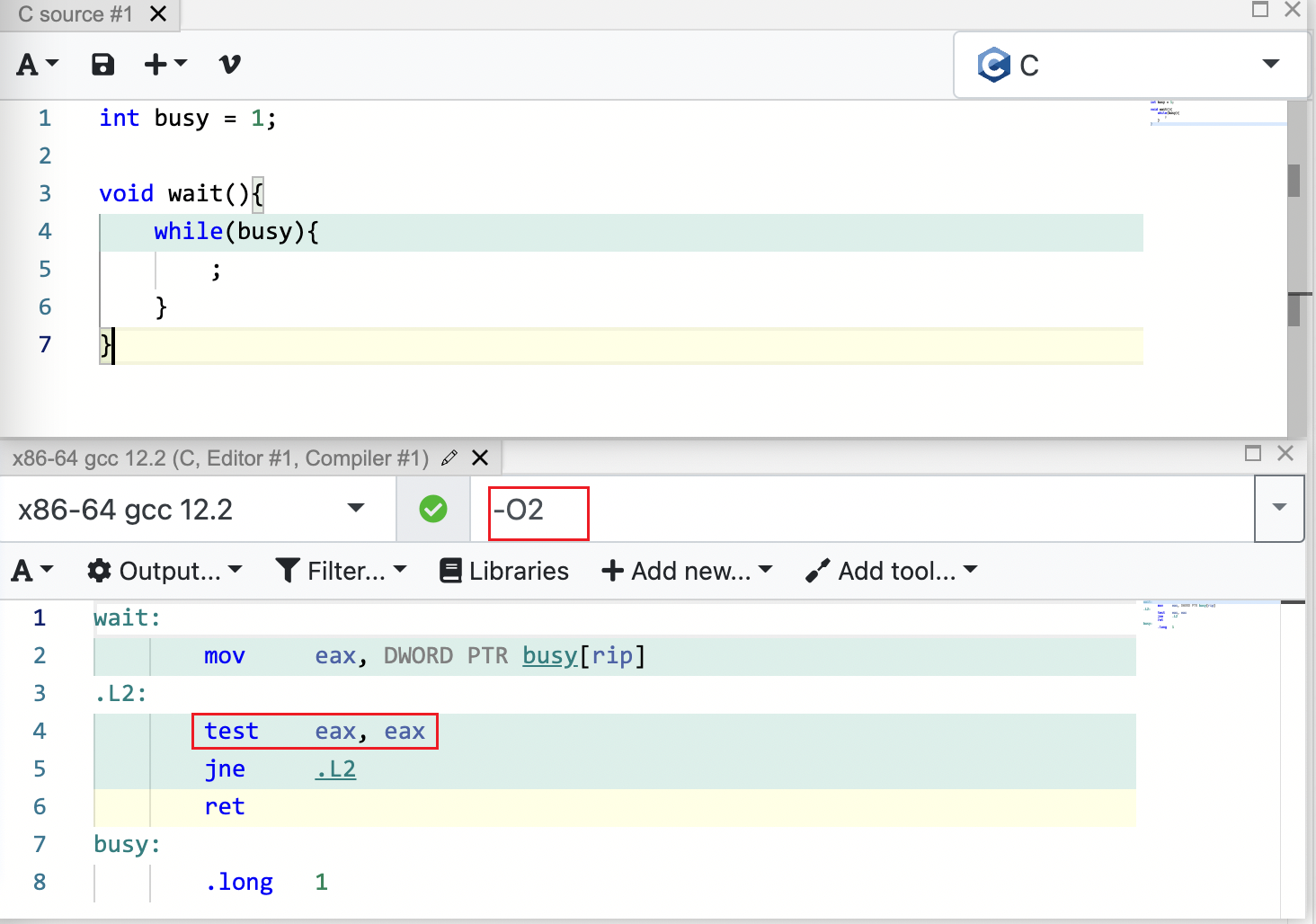
gcc -O0 -O1 -O2 -O3 四级优化选项及每级分别做什么优化
在线编译:https://godbolt.org/
如下图: 使用-O2编译优化时,常量替换导致直接 test eax eax,不会再读取内存变量, 无法退出循环。